
Building Blockchain ETL? Wait! Read this first!
As the adoption of blockchain continues to expand, companies are seeking ways to extract meaningful insights. To extract these insights from blockchain data, it is essential to develop a robust ETL pipeline that is specifically designed for this purpose.
However, building such an ETL, whether it involves data from multiple blockchains or a single one, comes with its own set of distinctive challenges.
In this article, we delve into the key challenges encountered when building blockchain ETL pipelines. By understanding these challenges, you can develop strategies to overcome them.
Challenges with Blockchain ETL
Anyone building a blockchain ETL pipeline needs to understand these challenges to better navigate the complexities of working with blockchain data and optimize ETL pipelines. Challenges with blockchain ETL range from data challenges to the availability of tools to build these ETL pipelines.
Let’s dive into each challenge in detail.
Data Indexing
Indexing blockchain data is a time-consuming process that can span weeks or months, depending on the size of the blockchain. For example, the Ethereum blockchain size is approximately 14.5TB. Indexing the blockchain like that means processing and organizing 14.5TB of data, which will take a while depending on your requirements.
Constant changes in data demand and any issues during indexing might require reindexing again, which is a resource-intensive task that involves reprocessing the entire blockchain. Depending on your requirements, creating an indexing service costs you anywhere from $1,700 to $43,800 per year. For example, here are the hardware requirements for running a graph protocol node:
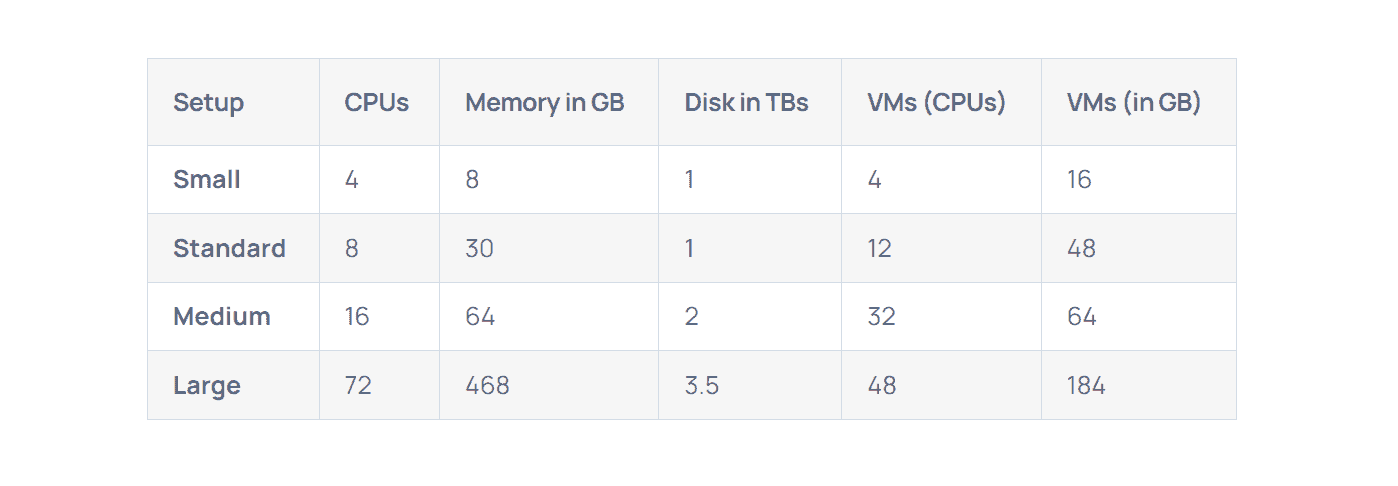
Data indexing plays a vital role in the ETL pipeline, enabling fast and efficient data access. By implementing robust error handling and data validation techniques, the need for reindexing can be minimized. Additionally, regular monitoring and maintenance of indexed data facilitate the early identification and resolution of potential issues.
Data Volume and Scalability
Processing and managing the significant data volume that blockchains generate is one of the main challenges in blockchain ETL. As the amount of data increases, so do the storage and processing requirements.
For example, the size of the Ethereum blockchain is 14.5 TB as of June 2023, and it keeps increasing every day by an average of 13-14 GB.
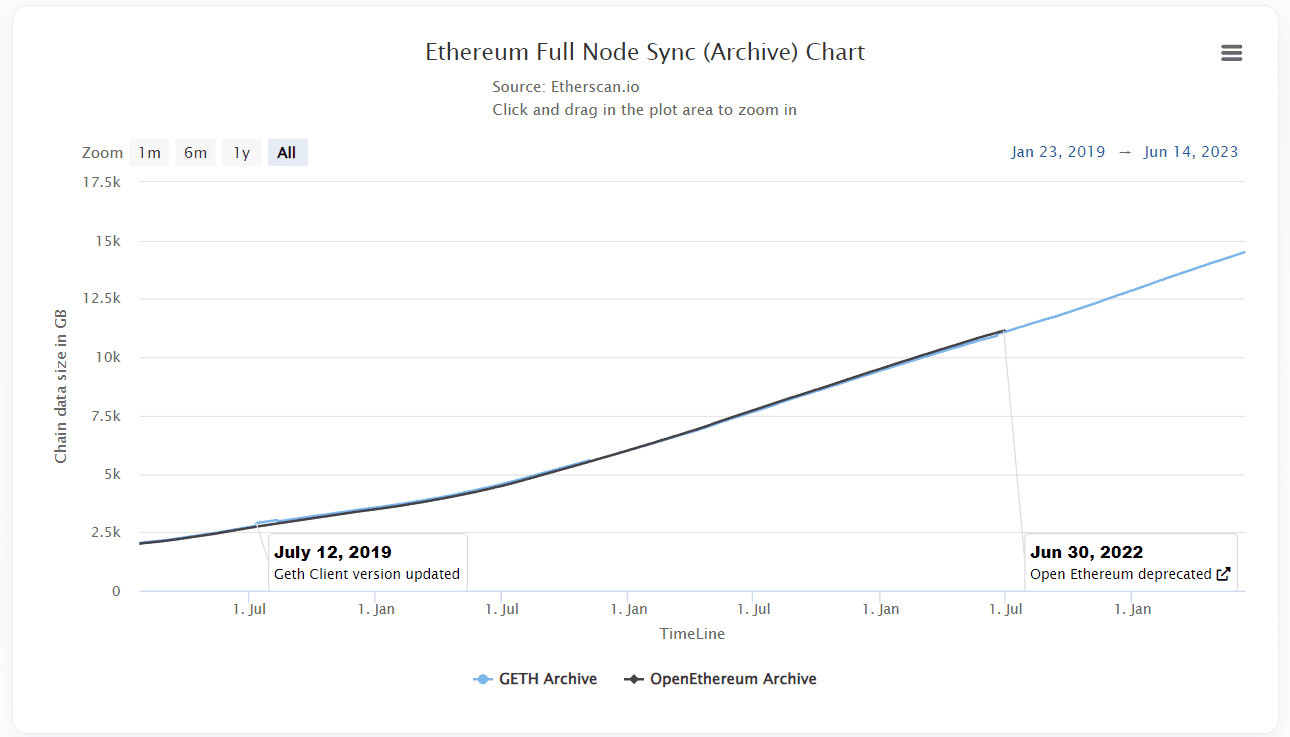
Scalability is essential to make sure the ETL pipeline can handle the high throughput of blockchain networks. Blockchain networks like Solana, which has a TPS rate ranging from 2-4k, need a different approach than Ethereum or Bitcoin when integrating those in the ETL pipeline.
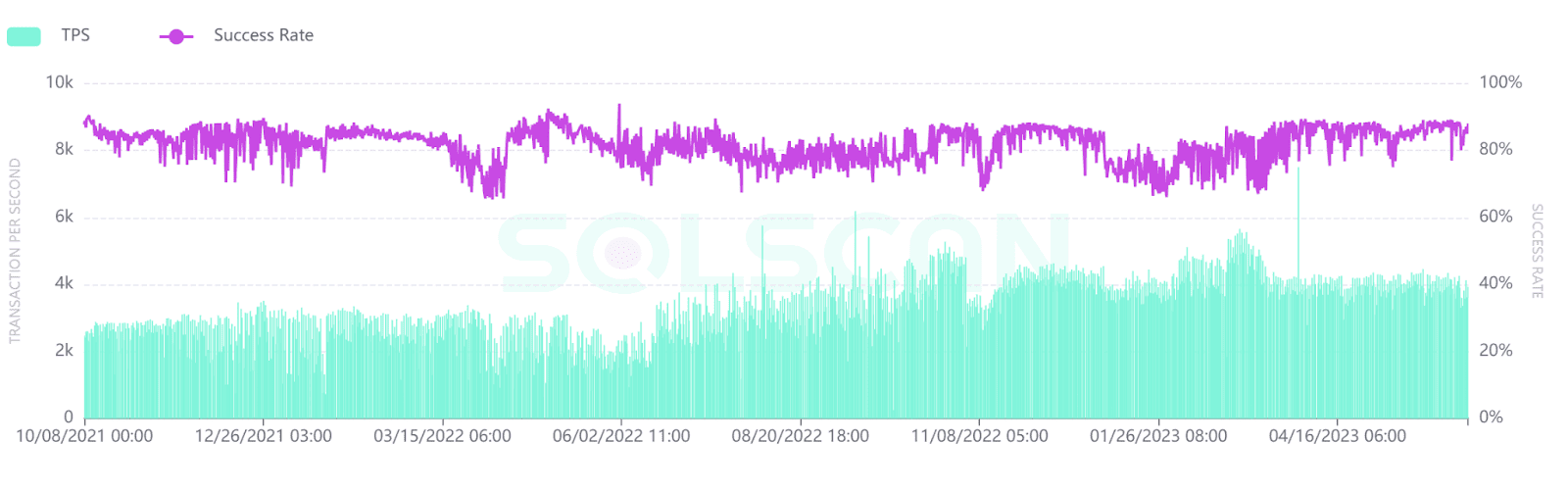
An effective ETL solution must be able to scale alongside the growing data volume, enabling seamless processing and storage of data from one or multiple blockchains.
Continuous Evolution of Blockchain Network
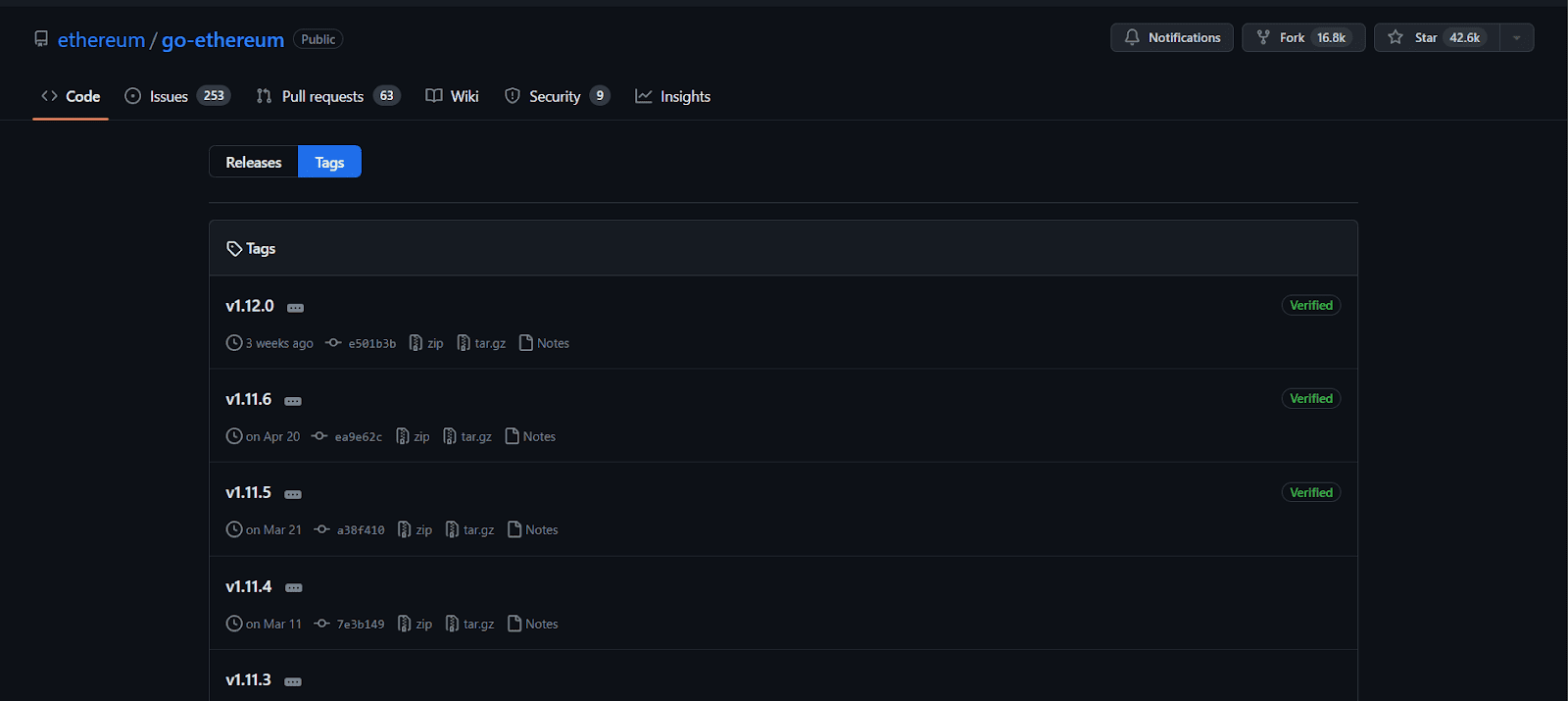
Blockchain networks are subject to frequent upgrades and reorganizations, which becomes a challenge for ETL pipelines. Upgrades bring changes to consensus algorithms, features, and bug fixes. Here is an example of Go-Ethereum client releases. As you can see, these releases happen very frequently, so ETL systems must adapt to these changes seamlessly, ensuring accurate data processing.
During a chain reorganization in a blockchain, the blocks that were previously considered correct may change. Reorg happens in chains frequently. Here is an example of blocks that are excluded from Ethereum due to reorgs. You can see how frequently those reorgs happen.
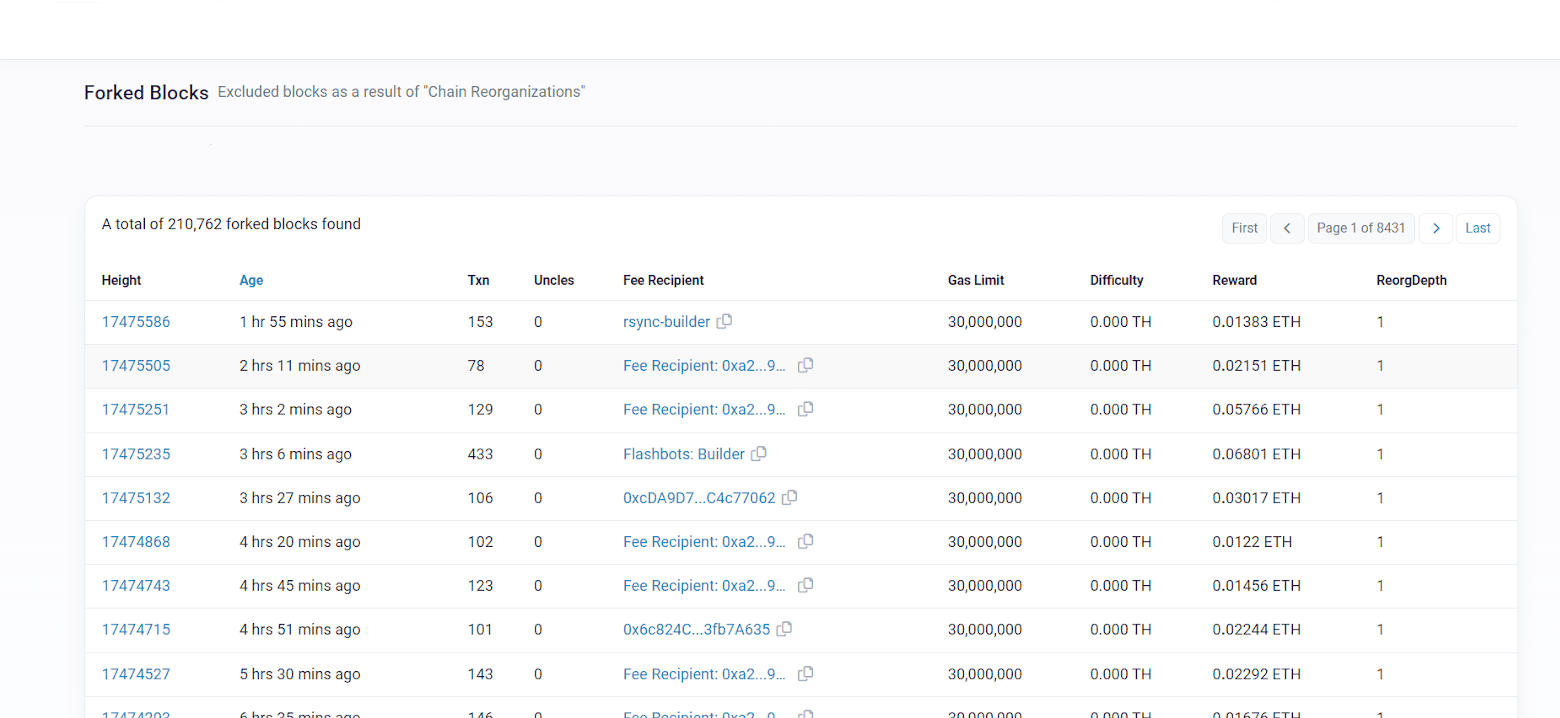
Sometimes the community might get divided and create a fork of a chain like Ethereum and Ethereum Classic or Bitcoin and Bitcoin Cash. For instance, Ethereum Classic experienced a notable fork, as discussed in our blog post on the Ethereum Classic 51% attack. These cases are rare, but it is important to update the data in the ETL pipeline based on the current consensus of the blockchain network to ensure the accuracy of the processed data.
Data Structure and Complexity
Handling different data structures from various blockchains presents unique challenges in building an ETL pipeline. Let’s look at how transactions differ in Bitcoin, Solana, and Ethereum.
Bitcoin uses a UTXO model, tracking inputs and outputs to determine balances in the network.
In Solana, transactions can have multiple instructions, which are small units of execution logic in a program (also referred to as a “smart contract” on other blockchains).
In Ethereum’s account model, the network keeps track of accounts, which can represent individuals, organizations, or smart contracts. Each account has its own address and associated balance.
These differences in transaction structures make it challenging to build an ETL pipeline. Integrating multiple blockchains into a single pipeline adds complexity as you need to handle various data structures.
Data Quality Challenges
Maintaining high data quality is a critical aspect of the blockchain ETL pipeline.
While dealing with large amounts of data, the blockchain ETL pipeline will have missing or duplicate data. Missing or duplicate data can occur for various reasons, such as network issues or gaps in data sources. Implementing robust data validation techniques and error handling mechanisms is essential to minimizing the impact of missing or duplicate data on the overall pipeline.
Blockchain data can be complex and require careful interpretation. Data engineers need to understand the intricacies of blockchain networks, such as different transaction types, smart contracts, and token standards. Misinterpreting or misrepresenting data can result in incorrect analysis and decision-making. Ensuring data engineers have a deep understanding of blockchain concepts and protocols is essential for accurate data interpretation.
Hiring skilled data engineers in the blockchain space can be expensive. The demand for experienced professionals with expertise in blockchain technology and ETL processes often drives up the average salary.
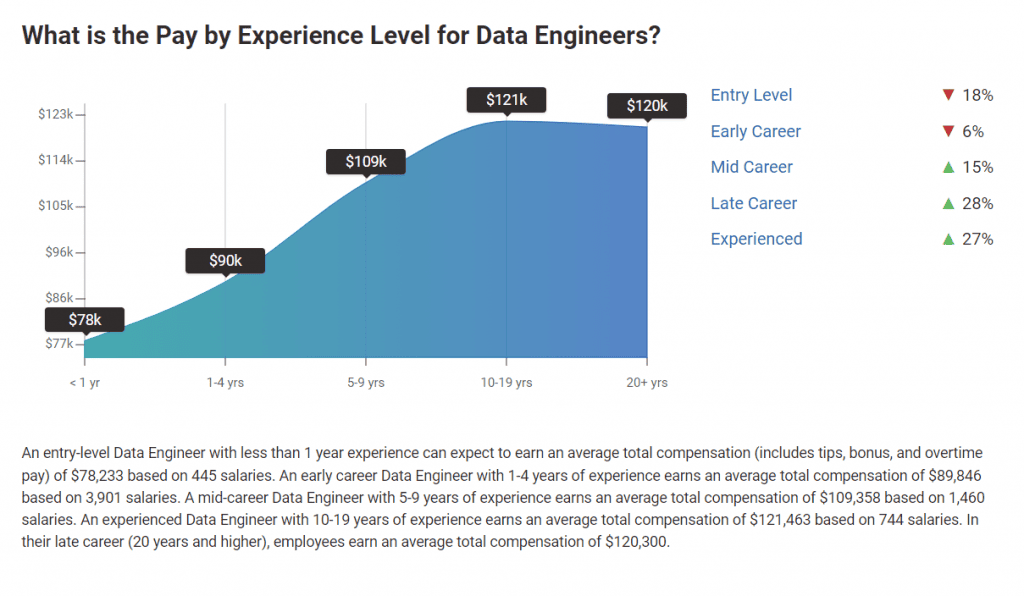
By implementing robust data validation techniques and deduplication mechanisms and investing in skilled data engineers, organizations can overcome these challenges and ensure the reliability and accuracy of their blockchain ETL pipelines.
Open-Source ETL Softwares
When it comes to building a blockchain ETL pipeline, you have two options: building a custom solution or using existing open-source tools. Custom solutions take a lot of time, can be error-prone, and may not scale well.
On the other hand, open-source ETL software provides pre-built functionality and faster implementation. Finding ETL software for popular blockchains like Bitcoin and Ethereum is very simple. One of the popular open source ETL software for Ethereum networks is ethereum-etl, which has been maintained over the years, as you can see in the following chart:
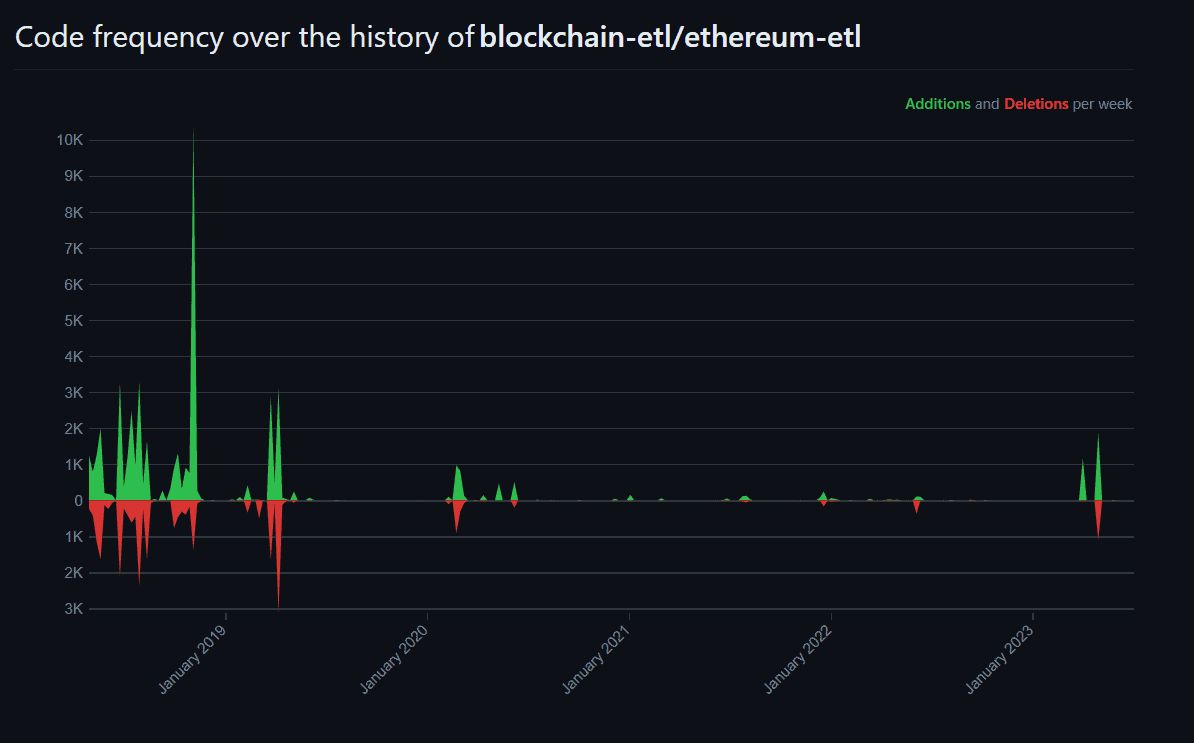
However, finding open-source solutions for some blockchains can be challenging, and there might not be active community support for every open-source solution. For some blockchains, you will find them open-source, but they might not be maintained to keep up with changes happening in the network. Here are open-source solutions for Solana, EOS, and Tezos.
For other chains like Algorand, Flow, Harmony, etc., there are no open-source alternatives available.
Publicly Available Blockchain Datasets
There are public datasets available for different blockchains provided by platforms like Google Bigquery and AWS that offer convenient access for ETL pipelines.
However, it’s important to note that publicly available datasets on platforms like Google BigQuery and AWS have certain limitations. These datasets may have data delays and schema constraints, and they provide data for a limited number of blockchain networks.
The limitations of these datasets include the number of blockchain offerings and the frequency of updates. Instead of real-time updates, these datasets are typically updated on a daily basis. As a result, if your ETL pipeline relies solely on these public datasets, it may lag behind the most current data by up to a day.
While these publicly available datasets offer basic information such as transactions, blocks, and traces, they may not provide comprehensive data for specific use cases like contract calls or decentralized finance (DeFi) trade data. It’s important to consider these limitations and assess whether additional data sources or alternative approaches are required to fulfill your specific data needs.
Node Reliance
When it comes to using blockchain nodes to consume blockchain data, it’s important to consider the issues with relying on blockchain nodes. Blockchain nodes can face technical problems, experience downtime, or provide inconsistent data.
For example, if a node encounters technical problems or goes offline, it can cause delays and incomplete data extraction, leading to gaps in the dataset.
A robust ETL pipeline should utilize more than one node to make the system redundant and minimize issues that might arise from relying on a single node.
Real-Time Data Challenge
Real-time data processing presents significant challenges in blockchain ETL. Due to the continuous operation and frequent updates of blockchains, different nodes may have varying views of the current state.
In a blockchain network, when multiple blocks are generated, the network reaches a consensus to determine which block is considered valid and adds it as the latest block in the chain. This consensus mechanism ensures that all participants in the network agree on the current state of the blockchain and adds the chosen block to maintain a consistent and accurate record of transactions. As a result, other blocks at the same height are discarded, potentially eliminating multiple branches that are not attached to the latest block in the chain.
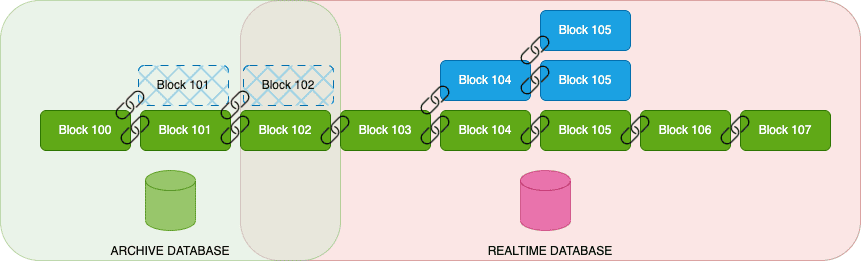
Achieving a definitive and consistent state takes time due to the consensus mechanism. ETL processes must effectively adapt to these changing network states, ensuring data synchronization, consistency, and reliability despite potential delays.
How is Bitquery Addressing these Problems?
Bitquery offers you different solutions related to indexed blockchain data, but if you’re building blockchain ETL, Bitquery Streaming APIs and Data in Cloud products will solve most of the challenges that we discussed above.
With Bitquery’s Streaming APIs, you can access real-time and live data, ensuring that your ETL pipeline has accurate and up-to-date information. These APIs are designed to provide reliable and timely data for the Ethereum, BSC, and Arbitrum networks, with more networks being added soon.
Bitquery’s Data in Cloud product is ideal for ETL pipelines consuming Ethereum data. It provides a comprehensive dataset from the Ethereum mainnet, including raw and post-processed data. This enables efficient processing and analysis, allowing you to build a robust and effective ETL pipeline tailored to Ethereum.
Conclusion: Should I Build the Entire ETL Pipeline?
When considering whether to build the entire ETL pipeline yourself or outsource certain parts to service providers, several factors come into play.
If your ETL pipeline is for a non-time-sensitive purpose or focuses on a limited number of blockchains, building your own solution or using freely available data may be viable options, given the lower complexity involved.
However, for time-sensitive ETL pipelines or those integrating multiple blockchains, outsourcing certain aspects, such as data indexing, to specialized service providers like Bitquery can be a more practical approach. This allows you to leverage their expertise and existing infrastructure, saving time and reducing the costs associated with maintaining the entire pipeline.
Ultimately, the decision to build or buy depends on the specific requirements of your project, balancing complexity, time sensitivity, and associated costs.
Subscribe to our newsletter
Subscribe and never miss any updates related to our APIs, new developments & latest news etc. Our newsletter is sent once a week on Monday.


