Building a Blockchain Intelligence System
You must have heard about MicroStrategy if you are in crypto, but do you know MicroStatergy sells BI (Business intelligence) tools. Business intelligence tools used by enterprises for decades to make business decisions based on historical, current, and predictive views of business operations.
In Web2, BI tools are used by companies to understand their own data. However, in Web3, we are in a different paradigm. Unlike Web2, where companies own their data behind closed doors. In Web3, data is openly accessible to analyze, find financial opportunities & anomalies, and build intelligent products.
Even though blockchain data is openly accessible, analyzing for useful, actionable insights is still a complicated task.
Raw data is dumb; we need intelligence
Blockchains only produce transactions and events. These transactions and events are raw data that can’t answer intelligent questions. For example, let me ask you a few questions —
- What is the median income of liquidity providers in the Dex market?
- How many new loans issued on Compound or Aave, and how many of those are returning users? And what are the predictions for total loan volume in 2021?
- What is the top destination for X token? Is it an exchange, crypto service, or a DeFi protocol?
- How to analyze if there is any wash trading on any DEX?
- What is the average income of liquidity providers on the Ethereum vs. Binance chain?
- How to analyze if a specific transaction is risky and money is coming from an illegitimate source?
- What is the average price of all Cryptokitties sold till now?
- How many bitcoin addresses are in a profitable state since its inception?
There are so many questions that can be answered by analyzing and applying different algorithms on blockchain data. However, it’s not easy.
Blockchains have a big data problem
Blockchain events and transactions contain data from millions of wallets, smart contracts, interacting with each other, and end-users. As technology is maturing, we see more complex smart contract structures.
However, to turn this raw data into decision making information, we need highly sophisticated data pipelines processing billions of transactions and events every day and transforming them into insights.
Data mining and grouping it with other data sets are essential to provide meaningful blockchain information. For example, to make sense of DEX trades, we need to group blockchain data with market data. Another example, in blockchain money tracing, we apply heuristic and cluster algorithms to understand the money flow and recognize different services.
All this takes a lot of processing and data management, and intelligent algorithms.
Blockchain Intelligence and OLAP
We want to build a highly performative Blockchain intelligence system, which can compute billions of rows in seconds to answer complex blockchain data questions. This is why our technology stack is an OLAP system (Online analytical processing). But what is OLAP?
OLAP (Online Analytical Processing) is the backbone for many Business Intelligence (BI) applications. It is a powerful technology for data discovery, including capabilities for limitless reporting, viewing, complex analytical calculations, and predictive “what if” scenario (budget, forecast) planning.
Unlike relational databases, OLAP tools do not store individual transaction records in two-dimensional, row-by-column format, like a worksheet. Instead, they use multidimensional database structures — known as Cubes in OLAP terminology — to store arrays of consolidated information.[1]
Bitquery Architechture
Let’s understand how we built our infrastructure to enable scalable analytical processing. In the simplest form, we are using Clickhouse (An OLAP database) at our data warehouse and built a GraphQL layer on top of it, and glued them together using a library called Activecube, which we have written from scratch and open-sourced. This library transforms GraphQL queries to Clickhouse queries.
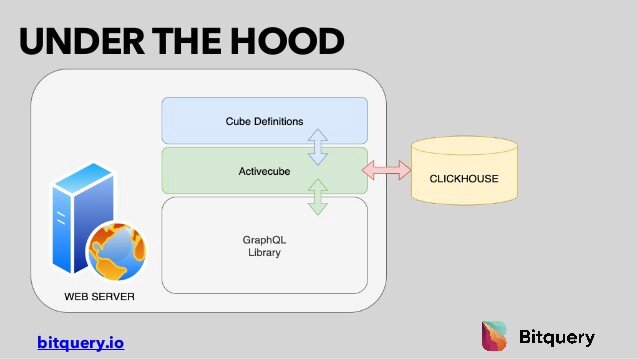
Now, Let’s dig deep and learn how our system works and its capabilities.
Cube
We store blockchain data in cubes. Cube is a shorthand for multidimensional dataset, given that data can have an arbitrary number of dimensions. A cube is not a “cube” in the strict mathematical sense, as all the sides are not necessarily equal. To analyze more complex data, we create hypercubes using multiple cubes.
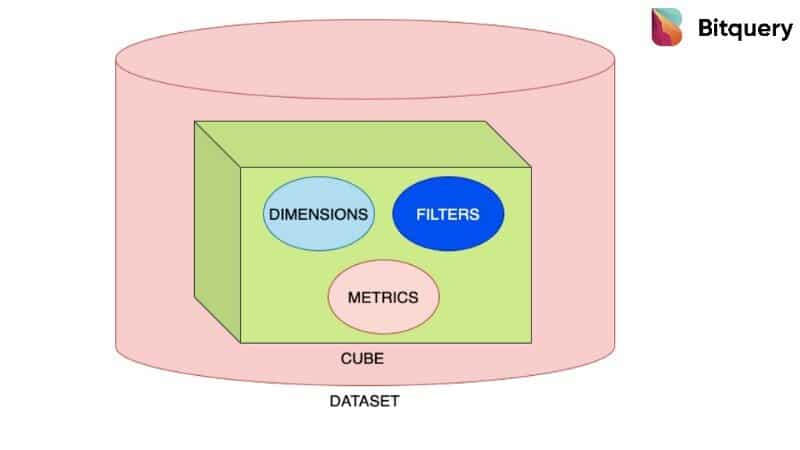
In our case, a typical cube contains dimensions, filters, and metrics. Let me break this down for you.
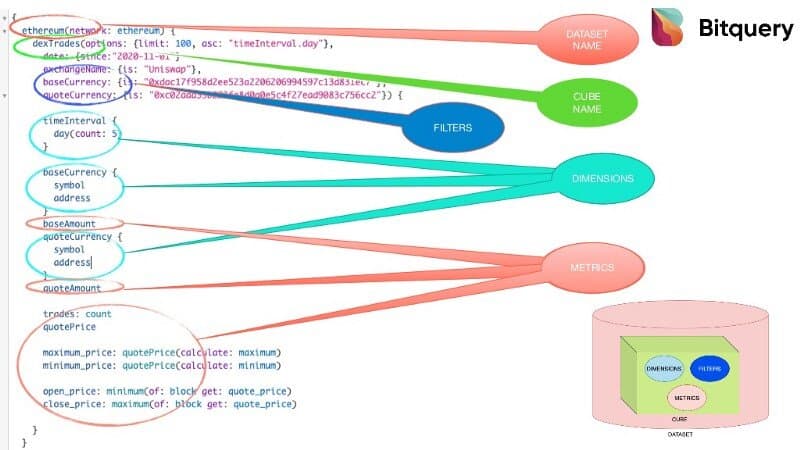
Check out the following GraphQL query, which provides DEX trades for USDT/WETH pair on Uniswap DEX. As you can see, it contains multiple attributes.
- Dataset (Ethereum in this case)
- DexTrades (Cube name)
- Filters (Exchange name, Base currency, Quote currency, etc.)
- Dimensions (Time interval, Base currency, Quote currency)
- Metrics (Base amount, Traders count, Quote price, etc..)
let’s understand them one by one.
Dimensions
Dimensions are defined in the GraphQL schema and have multiple attributes. And Attributes are like sub-dimensions which helps in getting specific data or performing aggregations. Attributes can be multi-level.
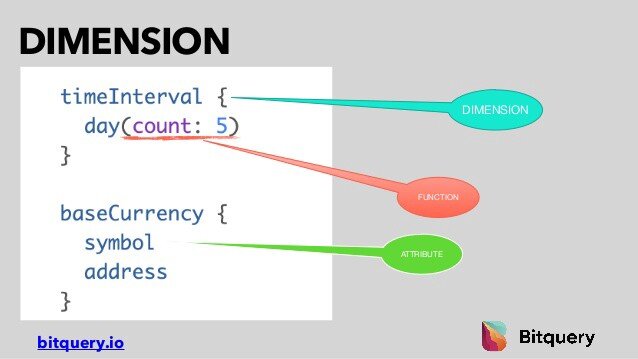
Attributes have functions to enable aggregation. Note, What we call functions, Graphql specifications call them attributes, but we add special meaning to it.
In the above example, day has function count, so it’s helping in aggregating every five days. You can multiple functions enabling different functionality throughout our schema.
So as I said before, functions do not exist on Graphql specification, but we added them to make our queries programmatical, this enhances the capabilities of our queries because we provide a lot of functions and continuously add new functions to enable new functionalities. This is the way we map GraphQL with analytics and add programming capabilities to our queries.
Metrics
Metrics look similar to Dimensions, however, they behave differently. For example, metrics are usually numerics and they calculate maximum, minimum, and other mathematic functions.

Dataset and Filters
Datasets are types of data such as Ethereum and Binance smart chain, both are Ethereum type datasets because they are similar types of blockchains. Filters help in adding scope and range to queries.
Integrated and Embedded Blockchain intelligence
We think blockchain intelligence integrated with different systems will unlock the immense potential of blockchain applications or DApps. There are tons of potential integrations with Web2 applications that can enhance blockchain data’s value and help in decision making and improving blockchain products.
At Bitquery, we are deeply committed to building open platforms, which can be integrated or embedded in other applications. We are currently working on Bitquery IDE, a one-stop-shop for developers and analysts to work with blockchain data. We will also launch “Flexigraph” soon, which will allow anyone to create their own schema and deploy them on our infra to process data based on their need.
Check out our Github and if you have any questions, let us know on our Telegram channel.
Also Read:
- A marriage of Market data with Blockchain data
- The Graph vs Bitquery – Solving Blockchain Data Problems
- Eating blockchain data using GraphQL spoon
- Best Blockchain Analysis Tools and How They Work?
- ETH2.0 Analytical Explorer, Widgets, and GraphQL APIs
About Bitquery
Bitquery is a set of software tools that parse, index, access, search, and use information across blockchain networks in a unified way. Our products are:
-
Coinpath® APIs provide blockchain money flow analysis for more than 24 blockchains. With Coinpath’s APIs, you can monitor blockchain transactions, investigate crypto crimes such as bitcoin money laundering, and create crypto forensics tools. Read this to get started with Coinpath®.
-
Digital Assets API provides index information related to all major cryptocurrencies, coins, and tokens.
-
DEX API provides real-time deposits and transactions, trades, and other related data on different DEX protocols like Uniswap, Kyber Network, Airswap, Matching Network, etc.
If you have any questions about our products, ask them on our Telegram channel. Also, subscribe to our newsletter below, we will keep you updated with the latest in the cryptocurrency world.
Subscribe to our newsletter
Subscribe and never miss any updates related to our APIs, new developments & latest news etc. Our newsletter is sent once a week on Monday.


